
 PhD student @ Northeastern University
PhD student @ Northeastern UniversityI am a third-year Ph.D. student in Computer Science at Northeastern University (China), supervised by Prof. Ge Yu and Prof. Yanfeng Zhang.
I’m interested in building distributed and parallel graph processing systems. I am also interested in GPU-accelerated data management.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Northeastern UniversityPh.D. StudentSep. 2023 - present
-
Northeastern UniversityM.S. in Computer ScienceSep. 2021 - Jul. 2023
-
Northeastern UniversityB.S. in Computer ScienceSep. 2017 - Jul. 2021
Honors & Awards
-
Outstanding Master’s Thesis Award of the Chinese Institute of Electronics (中国电子学会优秀硕士论文)2025
-
“China Computer Federation–Huawei MindSpore AI Computing Acceleration Program” research grant (“中国人工智能学会-华为AI算力加速计划”科研资助项目)2025
-
National Natural Science Foundation Youth Student Basic Research Project, PhD Student (国家自然科学基金青年学生基础研究项目)2025
-
China Association for Science and Technology (CAST) Young Talent Support Program, PhD Student (中国科协青年科技人才培育工程博士生专项计划)2025
-
National Scholarship of China2025
-
National Scholarship of China2024
-
The champion in China’s first CCF Graph Computing Challenge2023
Selected Publications (view all )
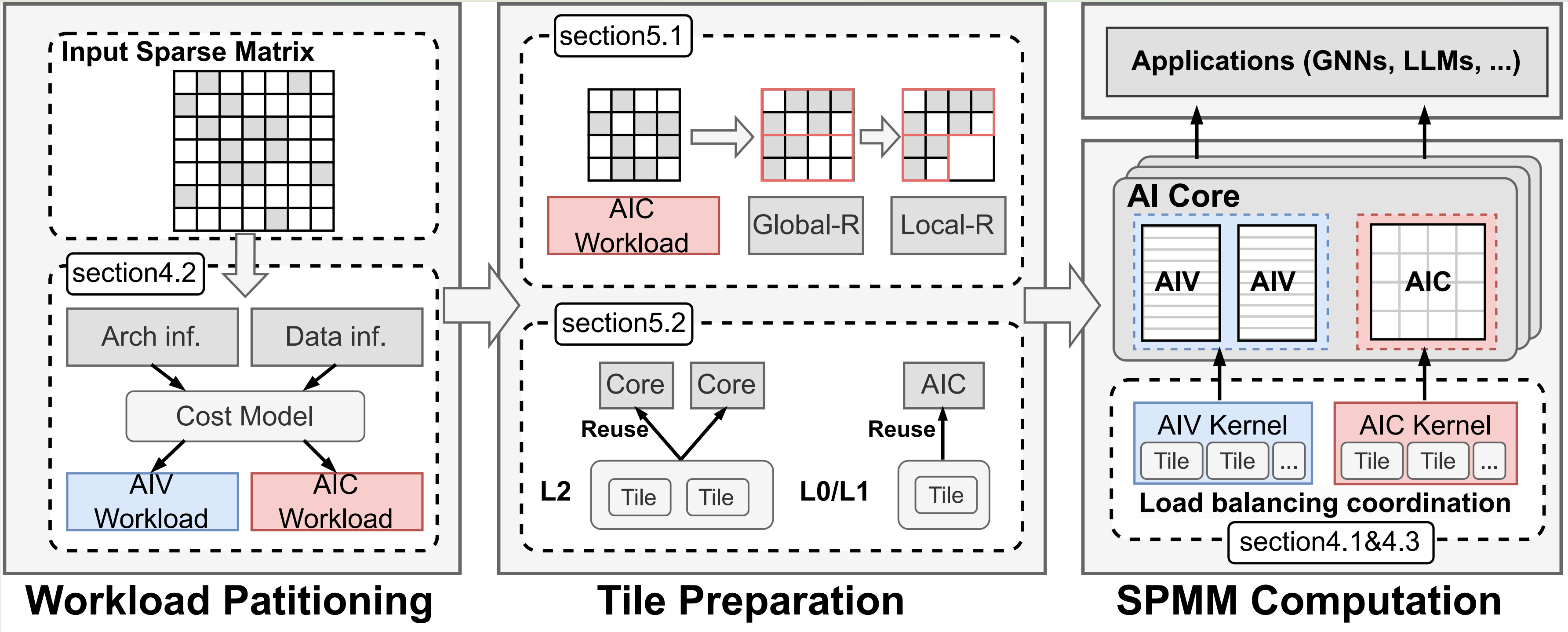
NeutronSparse: Coordinating Heterogeneous Engines for Sparse Matrix Multiplication on NPUs
Xin Ai, Zeyu Ling, Hao Yuan, Qiange Wang, Yanfeng Zhang, Yutao Peng, Ge Yu
Proceedings of the International Conference on Management of Data (SIGMOD) 2027
Sparse matrix–matrix multiplication is a fundamental operation for large-scale sparse data processing, but high-performance SpMM on NPUs remains challenging because irregular sparsity requires efficient data organization and scheduling across heterogeneous compute units. We identify that the main bottleneck on Ascend NPUs comes from insufficient coordination under the tile-based execution model, which limits compute utilization and causes redundant data movement. To address this, we propose NeutronSparse, a coordination-first SpMM framework that combines sparsity-aware workload balancing across heterogeneous engines with locality-aware tile orchestration to improve data reuse and execution efficiency.
NeutronSparse: Coordinating Heterogeneous Engines for Sparse Matrix Multiplication on NPUs
Xin Ai, Zeyu Ling, Hao Yuan, Qiange Wang, Yanfeng Zhang, Yutao Peng, Ge Yu
Proceedings of the International Conference on Management of Data (SIGMOD) 2027
Sparse matrix–matrix multiplication is a fundamental operation for large-scale sparse data processing, but high-performance SpMM on NPUs remains challenging because irregular sparsity requires efficient data organization and scheduling across heterogeneous compute units. We identify that the main bottleneck on Ascend NPUs comes from insufficient coordination under the tile-based execution model, which limits compute utilization and causes redundant data movement. To address this, we propose NeutronSparse, a coordination-first SpMM framework that combines sparsity-aware workload balancing across heterogeneous engines with locality-aware tile orchestration to improve data reuse and execution efficiency.
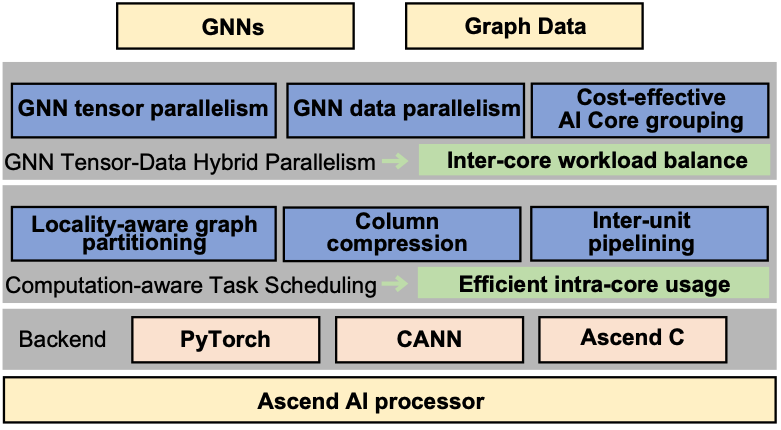
NeutronAscend: Optimizing GNN Training with Ascend AI Processors
Xin Ai, Bing Zhang, Qiange Wang, Yanfeng Zhang, Hao Yuan, Shufeng Gong, Ge Yu
ACM Transactions on Architecture and Code Optimization (TACO) 2025
The Ascend AI processor is typically architected on multiple AI Cores that are physically decoupled and designed for dense matrix computation. When processing graph data with inherent sparsity and power-law distribution, the Ascend AI processors suffer from the inter-core workload imbalance and inefficient intra-core resource utilization. In this paper, we present NeutronAscend, an efficient GNN training framework tailored for the Ascend AI processor. NeutronAscend employs two critical designs for both inter-core and intra-core performance optimization.
NeutronAscend: Optimizing GNN Training with Ascend AI Processors
Xin Ai, Bing Zhang, Qiange Wang, Yanfeng Zhang, Hao Yuan, Shufeng Gong, Ge Yu
ACM Transactions on Architecture and Code Optimization (TACO) 2025
The Ascend AI processor is typically architected on multiple AI Cores that are physically decoupled and designed for dense matrix computation. When processing graph data with inherent sparsity and power-law distribution, the Ascend AI processors suffer from the inter-core workload imbalance and inefficient intra-core resource utilization. In this paper, we present NeutronAscend, an efficient GNN training framework tailored for the Ascend AI processor. NeutronAscend employs two critical designs for both inter-core and intra-core performance optimization.
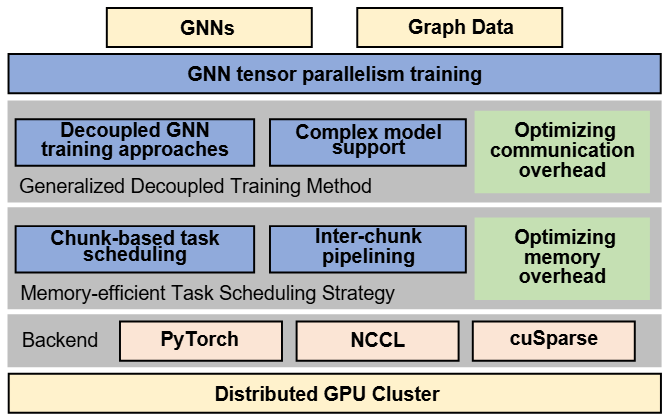
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
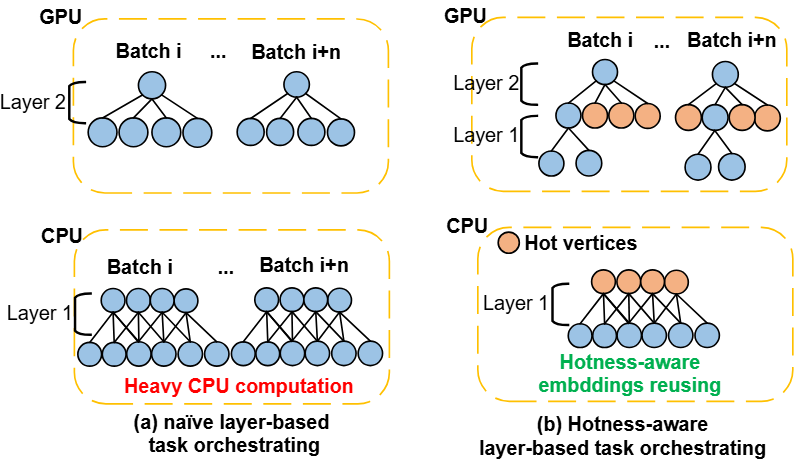
NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments
Xin Ai, Qiange Wang, Chunyu Cao, Yanfeng Zhang, Chaoyi Chen, Hao Yuan, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
In this paper, we propose NeutronOrch, a system for sample-based GNN training that incorporates a layer-based task orchestrating method and ensures balanced utilization of the CPU and GPU. NeutronOrch decouples the training process by layer and pushes down the training task of the bottom layer to the CPU. This significantly reduces the computational load and memory footprint of GPU training.
NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments
Xin Ai, Qiange Wang, Chunyu Cao, Yanfeng Zhang, Chaoyi Chen, Hao Yuan, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
In this paper, we propose NeutronOrch, a system for sample-based GNN training that incorporates a layer-based task orchestrating method and ensures balanced utilization of the CPU and GPU. NeutronOrch decouples the training process by layer and pushes down the training task of the bottom layer to the CPU. This significantly reduces the computational load and memory footprint of GPU training.