
 PhD student @ Northeastern University
PhD student @ Northeastern UniversityI am a second-year Ph.D. student in Computer Science at Northeastern University (China), supervised by Prof. Ge Yu and Prof. Yanfeng Zhang.
I’m interested in building distributed and parallel graph processing systems. I am also interested in GPU-accelerated data management.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Northeastern UniversityPh.D. StudentSep. 2023 - present
-
Northeastern UniversityM.S. in Computer ScienceSep. 2021 - Jul. 2023
-
Northeastern UniversityB.S. in Computer ScienceSep. 2017 - Jul. 2021
Honors & Awards
-
National Scholarship of China2024
-
The champion in China’s first CCF Graph Computing Challenge2023
Selected Publications (view all )
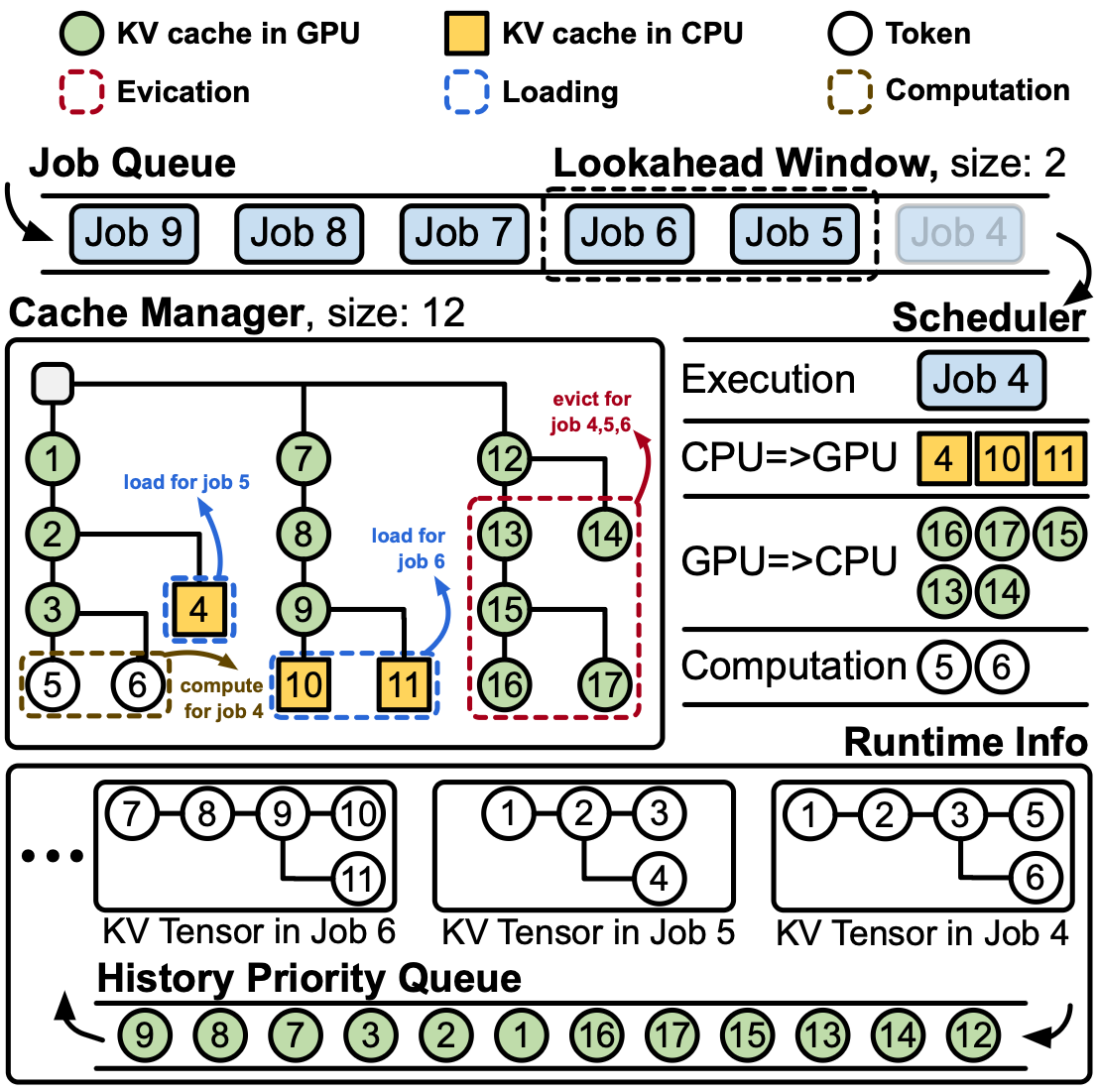
DepCache: A KV Cache Management Framework for GraphRAG with Dependency Attention
Hao Yuan, Xin Ai, Qiange Wang, Peizheng Li, Jiayang Yu, Chaoyi Chen, Xinbo Yang, Yanfeng Zhang, Zhenbo Fu, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2026
We introduce dependency attention, a novel graph-aware attention mechanism that restricts attention computation to token pairs with structural dependencies in the retrieved subgraph. Unlike standard self-attention that computes fully connected interactions, dependency attention prunes irrelevant token pairs and reuses computations along shared relational paths, substantially reducing inference overhead. Building on this idea, we develop DepCache, a KV cache management framework tailored for dependency attention.
DepCache: A KV Cache Management Framework for GraphRAG with Dependency Attention
Hao Yuan, Xin Ai, Qiange Wang, Peizheng Li, Jiayang Yu, Chaoyi Chen, Xinbo Yang, Yanfeng Zhang, Zhenbo Fu, Yingyou Wen, Ge Yu
Special Interest Group on Management of Data (SIGMOD) 2026
We introduce dependency attention, a novel graph-aware attention mechanism that restricts attention computation to token pairs with structural dependencies in the retrieved subgraph. Unlike standard self-attention that computes fully connected interactions, dependency attention prunes irrelevant token pairs and reuses computations along shared relational paths, substantially reducing inference overhead. Building on this idea, we develop DepCache, a KV cache management framework tailored for dependency attention.
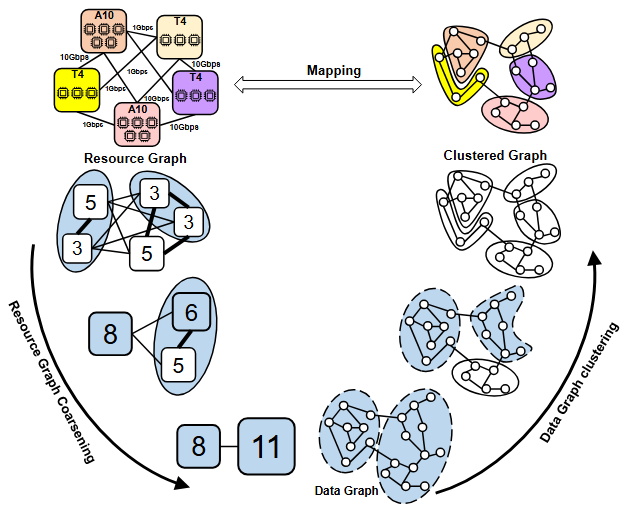
NeutronHeter: Optimizing Distributed Graph Neural Network Training for Heterogeneous Clusters
Chunyu Cao*, Xin Ai*, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Hao Yuan, Mingyi Cao, Chaoyi Chen, Yingyou Wen, Yu Gu, Ge Yu (* equal contribution)
Proceedings of the International Conference on Management of Data (SIGMOD) 2026
We present NeutronHeter, an efficient GNN training system for heterogeneous clusters. Our system leverages two key components to achieve its performance, including a multi-level workload mapping framework that transforms the complex multi-way mapping problem into a top-down workload mapping on a tree-like resource graph, and an adaptive communication migration strategy that reduces communication overhead by migrating communication from low-bandwidth links to local computation or high-bandwidth links.
NeutronHeter: Optimizing Distributed Graph Neural Network Training for Heterogeneous Clusters
Chunyu Cao*, Xin Ai*, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Hao Yuan, Mingyi Cao, Chaoyi Chen, Yingyou Wen, Yu Gu, Ge Yu (* equal contribution)
Proceedings of the International Conference on Management of Data (SIGMOD) 2026
We present NeutronHeter, an efficient GNN training system for heterogeneous clusters. Our system leverages two key components to achieve its performance, including a multi-level workload mapping framework that transforms the complex multi-way mapping problem into a top-down workload mapping on a tree-like resource graph, and an adaptive communication migration strategy that reduces communication overhead by migrating communication from low-bandwidth links to local computation or high-bandwidth links.
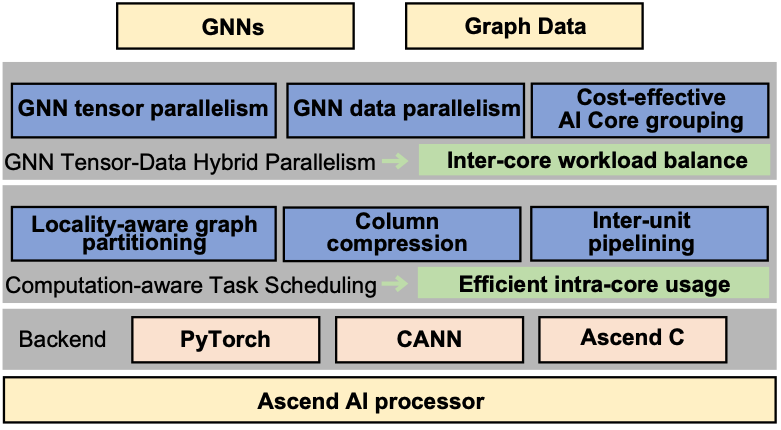
NeutronAscend: Optimizing GNN Training with Ascend AI Processors
Xin Ai, Bing Zhang, Qiange Wang, Yanfeng Zhang, Hao Yuan, Shufeng Gong, Ge Yu
ACM Transactions on Architecture and Code Optimization (TACO) 2025
The Ascend AI processor is typically architected on multiple AI Cores that are physically decoupled and designed for dense matrix computation. When processing graph data with inherent sparsity and power-law distribution, the Ascend AI processors suffer from the inter-core workload imbalance and inefficient intra-core resource utilization. In this paper, we present NeutronAscend, an efficient GNN training framework tailored for the Ascend AI processor. NeutronAscend employs two critical designs for both inter-core and intra-core performance optimization.
NeutronAscend: Optimizing GNN Training with Ascend AI Processors
Xin Ai, Bing Zhang, Qiange Wang, Yanfeng Zhang, Hao Yuan, Shufeng Gong, Ge Yu
ACM Transactions on Architecture and Code Optimization (TACO) 2025
The Ascend AI processor is typically architected on multiple AI Cores that are physically decoupled and designed for dense matrix computation. When processing graph data with inherent sparsity and power-law distribution, the Ascend AI processors suffer from the inter-core workload imbalance and inefficient intra-core resource utilization. In this paper, we present NeutronAscend, an efficient GNN training framework tailored for the Ascend AI processor. NeutronAscend employs two critical designs for both inter-core and intra-core performance optimization.
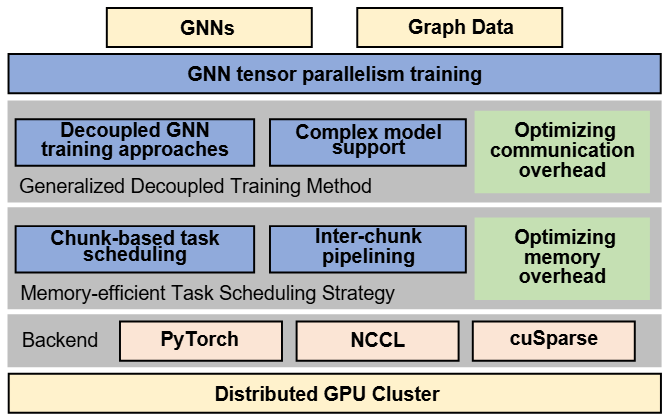
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism
Xin Ai, Hao Yuan, Zeyu Ling, Xin Ai, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2025
We present NeutronTP, a load-balanced and efficient distributed full-graph GNN training system. NeutronTP leverages GNN tensor parallelism for distributed training, which partitions feature rather than graph structures. Compared to GNN data parallelism, NeutronTP eliminates cross-worker vertex dependencies and achieves a balanced workload.
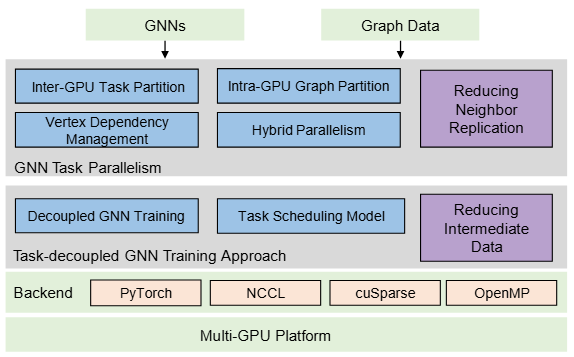
NeutronTask: Scalable and Efficient Multi-GPU GNN Training with Task Parallelism
Zhenbo Fu*, Xin Ai*, Qiange Wang, Yanfeng Zhang, Shizhan Lu, Chaoyi Chen, Chunyu Cao, Hao Yuan, Zhewei Wei, Yu Gu, Yingyou Wen, Ge Yu (* equal contribution)
Very Large Data Bases (VLDB) 2025
In this work, we propose NeutronTask, a multi-GPU GNN training system that adopts GNN task parallelism. Instead of partitioning the graph structure, NeutronTask partitions training tasks in each layer across different GPUs, which significantly reduces neighbor replication.
NeutronTask: Scalable and Efficient Multi-GPU GNN Training with Task Parallelism
Zhenbo Fu*, Xin Ai*, Qiange Wang, Yanfeng Zhang, Shizhan Lu, Chaoyi Chen, Chunyu Cao, Hao Yuan, Zhewei Wei, Yu Gu, Yingyou Wen, Ge Yu (* equal contribution)
Very Large Data Bases (VLDB) 2025
In this work, we propose NeutronTask, a multi-GPU GNN training system that adopts GNN task parallelism. Instead of partitioning the graph structure, NeutronTask partitions training tasks in each layer across different GPUs, which significantly reduces neighbor replication.
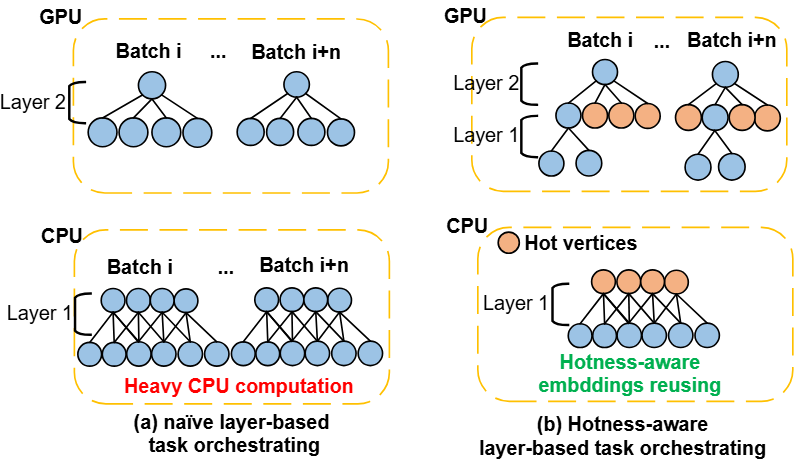
NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments
Xin Ai, Qiange Wang, Chunyu Cao, Yanfeng Zhang, Chaoyi Chen, Hao Yuan, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
In this paper, we propose NeutronOrch, a system for sample-based GNN training that incorporates a layer-based task orchestrating method and ensures balanced utilization of the CPU and GPU. NeutronOrch decouples the training process by layer and pushes down the training task of the bottom layer to the CPU. This significantly reduces the computational load and memory footprint of GPU training.
NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments
Xin Ai, Qiange Wang, Chunyu Cao, Yanfeng Zhang, Chaoyi Chen, Hao Yuan, Yu Gu, Ge Yu
Very Large Data Bases (VLDB) 2024
In this paper, we propose NeutronOrch, a system for sample-based GNN training that incorporates a layer-based task orchestrating method and ensures balanced utilization of the CPU and GPU. NeutronOrch decouples the training process by layer and pushes down the training task of the bottom layer to the CPU. This significantly reduces the computational load and memory footprint of GPU training.
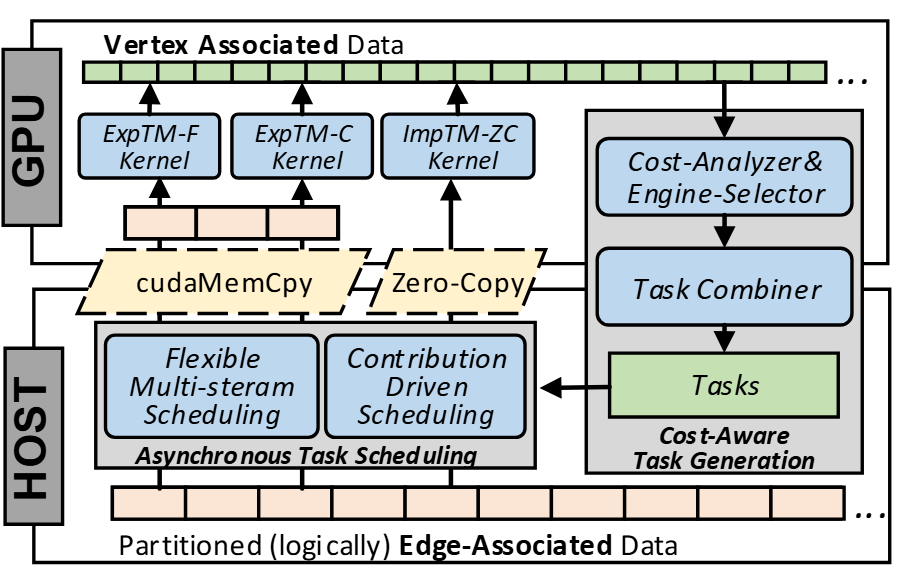
HyTGraph: GPU-Accelerated Graph Processing with Hybrid Transfer Management
Qiange Wang*, Xin Ai*, Yanfeng Zhang, Jing Chen, Ge Yu (* equal contribution)
International Conference on Data Engineering (ICDE) 2023
In this work, we propose a hybrid transfer management approach to take the merits of both the two approaches at runtime, with an objective to achieve the shortest execution time in each iteration. Based on the hybrid approach, we present HyTGraph, a GPU-accelerated graph processing framework, which is empowered by a set of effective task scheduling optimizations to improve the performance.
HyTGraph: GPU-Accelerated Graph Processing with Hybrid Transfer Management
Qiange Wang*, Xin Ai*, Yanfeng Zhang, Jing Chen, Ge Yu (* equal contribution)
International Conference on Data Engineering (ICDE) 2023
In this work, we propose a hybrid transfer management approach to take the merits of both the two approaches at runtime, with an objective to achieve the shortest execution time in each iteration. Based on the hybrid approach, we present HyTGraph, a GPU-accelerated graph processing framework, which is empowered by a set of effective task scheduling optimizations to improve the performance.